Category: Finance
-

p-‘s and q-‘s redux
Continuing our saga, trying to be intellectually honest, while a little prurient (Look It Up!, to adopt a recent political slogan), let’s look at the ridiculous “measured” correlation in point 3 of this public post. Let’s call it the PPP-GDP correlation! The scatter graph with data is displayed below Does…
-

The Rule of 72 – and what does the Swiss National Bank have to do with it
I was listening to an academic talk and someone mentioned the “Rule of 72”. Apparently invented by Einstein, it is a simple numerical approximation that helps you understand the power of compound interest. This, according to legend, became popular when interest rates offered on deposits by the Swiss National Bank…
-

Master Traders and Bayes’ theorem
Imagine you were walking around in Manhattan and you chanced upon an interesting game going on at the side of the road. By the way, when you see these games going on, a safe strategy is to walk on, since they usually reduce to methods of separating a lot of…
-
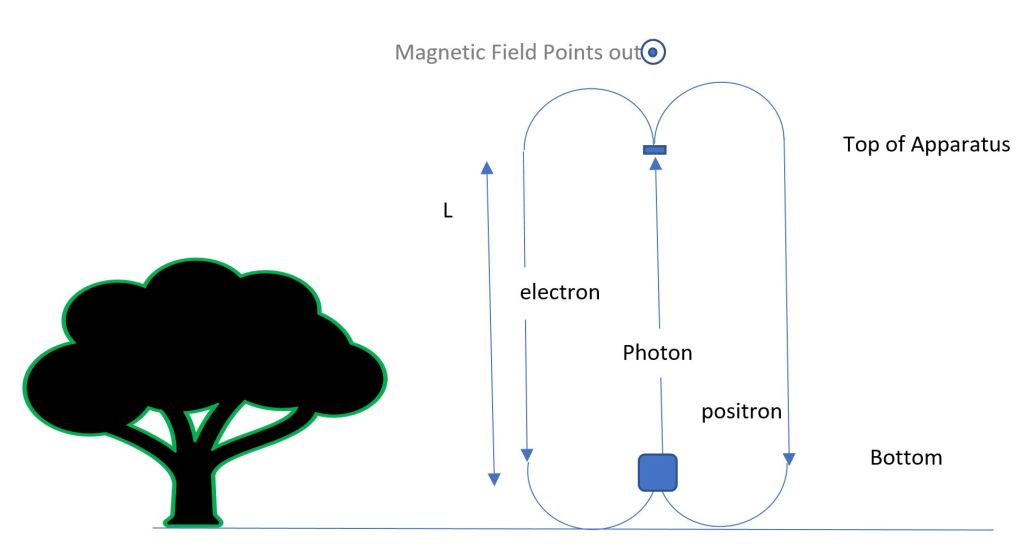
Arbitrage arguments in Finance and Physics
Arbitrage refers to a somewhat peculiar and rare situation in the financial world. It is succinctly described as follows. Suppose you start with an initial situation – let’s say you have some money in an ultra-safe bank that earns interest at a certain basic rate . Assume, also, that there…
