Category: Cosmology for Pedestrians
-

Hawking radiation: a weight-loss program for black holes – another black hole conundrum and a cute connection between black holes and quantum field theory
Coming on the heels of the apparent success of Wegovy and Ozempic for obese humans, a situation that I am still very skeptical about for its long-term effects, I thought I would write a post about how Hawking radiation causes black holes to lose mass. It is subtle and not…
-
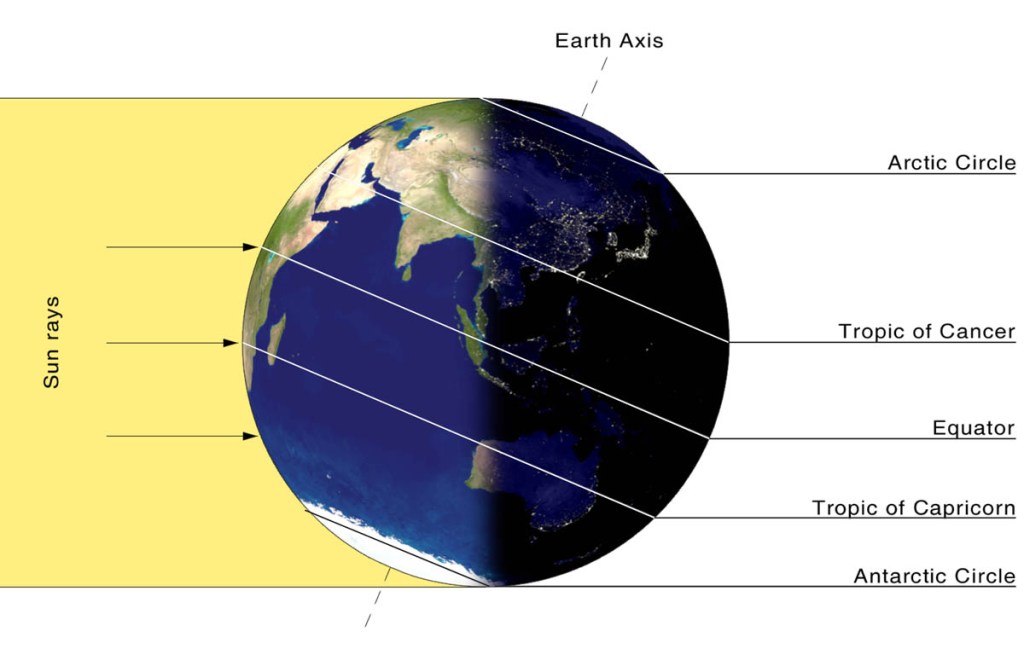
Is the longest day the warmest day?
I woke up to a snowy day on the 30th of December, here in New Jersey and immediately realized two things! It was colder and darker than at the same time on the shortest day of the year, the 21st of December. I suppose you could blame the colder weather…
-
New kinds of Cash & the connection to the Conservation of Energy And Momentum
Its been difficult to find time to write articles on this blog – what with running a section teaching undergraduates (after 27 years of ), as well as learning about topological quantum field theory – a topic I always fancied but knew little about. However, a trip with my daughter…
-

Mr. Olbers and his paradox
Why is the night sky dark? Wilhelm Olbers asked this question, certainly not for the first time in history, in the 1800s. That’s a silly question with an obvious answer. Isn’t that so? Let’s see. There certainly is no sun visible, which is the definition of night, after all. The…
-
Fermi Gases and Stellar Collapse – Cosmology Post #6
The most refined Standard Candle there is today is a particular kind of Stellar Collapse, called a Type 1a Supernova. To understand this, you will need to read the previous posts (#1-#5), in particular, the Fermi-Dirac statistics argument in Post #5 in the sequence. While this is the most mathematical…
-
A digression on statistics and a party with Ms. Fermi-Dirac and Mr. Bose (Post #5)
To explain the next standard candle, I need to digress a little into the math of statistics of lots of particles. The most basic kind is the statistics of distinguishable particles. Consider the following scenario. You’ve organized a birthday party for a lot of different looking kids (no twins, triplets,…
-

Cosmology: Cepheid Variables – or why Henrietta couldn’t Leavitt alone …(Post #4)
Having exhausted the measurement capabilities for small angles, to proceed further, scientists really needed to use the one thing galaxies and stars put out in plenty – light. The trouble is, to do so, we either need detailed, correct theories of galaxy and star life-cycles (so we know when they…
-
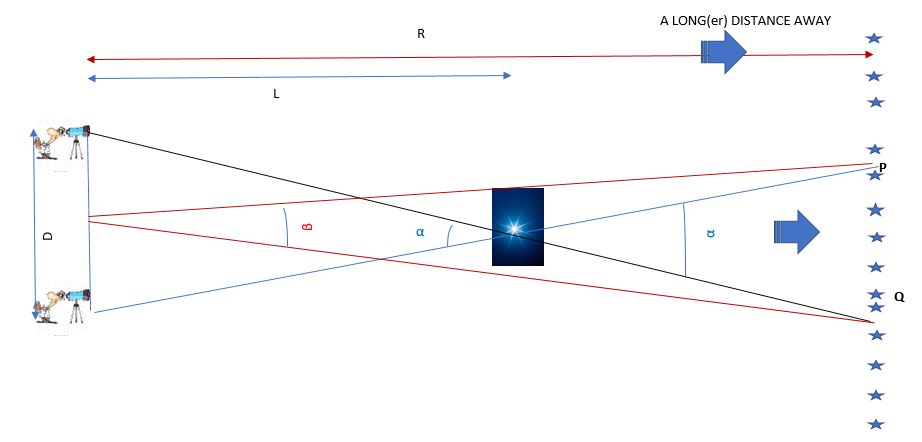
Cosmology: Distance Measurements – Parallax (Post #3)
This post describes the cool methods people use to figure out how far away stars and galaxies are. Figuring out how far away your friend lives is easy – you walk or drive at a constant speed in a straight line from your home to their house – then once…
-
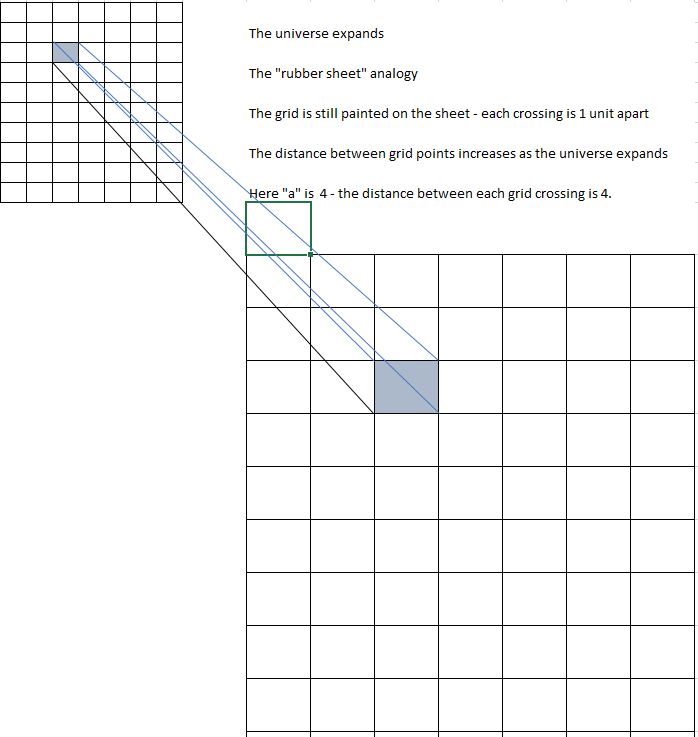
Cosmology and the Expanding Universe ..(Post #2)
Continuing the saga about the cosmological red-shift.
-
A course correction – and let’s get started!
I have received some feedback from people that felt the posts were too technical. I am going to address this by constructing a simpler thread of posts on one topic that will start simpler and stay conceptual rather than become technical. I want to discuss the current state of Cosmology,…
