Quantum Mechanics was the result of analysis of experiments that explored the emission and absorption spectra of various atoms and molecules. Once the electron and proton were discovered, very soon after the discovery of radioactivity, it was theorized that the atom was an electrically neutral combination of protons and electrons. Since it isn’t possible for a static arrangement of protons and electrons to be stable (a theorem in classical electromagnetism), the plum-pudding model of JJ Thomson was rejected in favor of one where the electrons orbited a central, heavy nucleus. However, it is well – known from classical electromagnetism that if an electron is accelerated, which is what happens when it revolves around the positively charged nucleus, it should radiate energy through electromagnetic radiation and quickly collapse into the nucleus.
The spectra of atoms and molecules were even more peculiar – there were observed an infinite number of specific spectral lines and no lines were observed at in-between frequencies. Clearly, the systems needed specific amounts of energy to be excited from one state to another and there wasn’t really a continuum of possible states from the ground state (or zero energy state) to high energies. In addition, the ground state of the hydrogen atom, for instance, seemed to have a specific energy, the ionization energy of the single electron in the atom that was specific to the hydrogen atom and could not be calculated from known parameters in any easy way. The relation between the lines was recognized by Rydberg – the frequency of the radiation emitted in various transitions in hydrogen was proportional to the difference of reciprocals of squares of small natural numbers.
Anyway, starting from an energy function (Hamiltonian) of the kind

For the single electron interacting with a heavy nucleus, we recover only the classical continuum of several possible solutions for the hydrogen atom, even neglecting the radiation of energy by the continuously accelerating electron.
We can state the conundrum as follows. We use the Energy function above, solve the classical problem and find that energy can take a continuum of values from some minimum negative number to infinity. In the lab, we find that Energy takes only a discrete infinity of values.
Let’s make a connection to matrices and operators. Matrices are mathematical objects that have discrete eigenvalues. Can we interpret 

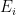
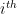


Now, if 

This leads us to the second realization, i.e., if we make this assumption that the eigenvectors
What is the physical significance of dot products such as 




This is akin to the probability density that a particle in state can be found in the state . The implication is that the magnitude of the dot product has physical meaning. Later, in an inspired leap of imagination, Max Born realized that we need to interpret the square of the magnitude as the quantity with physical meaning – the probability density.
What is the dot product of
Let’s start with some definitions, based on our simple minded notion that these variables need to be represented as matrices with eigenvectors.


The dot product is represented by

Now this must be a function purely of

We expect translational invariance in physics in our physically relevant quantities and 
Let’s take the dot product 

Now, if the origin of coordinates were moved by 

We don’t expect there to be a physical change in the dot product, it should not care about where the origin of coordinates is, up to a factor of magnitude unity. This means

In addition,

The simplest choice of function that has this property is (up to some units)

Where 


Since you also have

The above expression allows us to make the identification

So, the matrix

Now, suppose the eigenvectors of the


This is Schrodinger’s equation, if we make the interpretation

Apart from the mental leap to make from treating 
To see Nima Arkani-Hamed talk about the phrase “conservative-radicalism” and other interesting topics, see the YouTube video here.

Leave a comment