
In the practice of statistical inference, the concept of p-value (as well as something that needs to exist, but doesn’t yet, called q-value), is very useful. So is a really important concept you need to understand if you want to fool people (or prevent yourself from being fooled!) – it’s called p-hacking.
The first (p-value) concerns the following kind of question (I have borrowed this example from a public lecture at the Math Museum by Jen Rogers in September 2018) – suppose I have a deadly disease where it is known that, if you perform no treatment of any kind, 40% of the people that contract it die, while the others survive, i.e., the probability of dying is 

The second (I call this a q-value) concerns a sort of problem that crops up in finance. There are many retail investors that don’t have the patience to follow the market or follow the rise and fall of companies that issue stocks and bonds. They get ready-made solutions from their favorite investment bank – these are called structured notes. Structured notes can be “structured” any which way you want.
Consider one such example. Say you buy a 7-year US-dollar note exposed to the Nikkei-225 Japanese 225-stock index. The N225 index is the Japanese equivalent of the S&P500 index in the US Usually, you pay in $100 for the note, the bank unburdens you of $5 to feed the salesman and other intermediaries, then invests $70 in a “zero-coupon” US Treasury bond that will expire in 7 years. The Treasury bond is an IOU issued by the US Treasury – you give them $70 now (at the now prevailing interest rates) and they will return $100 in 7 years.
As far as we know right now, the US Treasury is a rock-solid investment, they are not expected to default, ever. Of course, governing philosophies change and someone might look at this article in a hundred years and wonder what I was thinking!
The bank then uses the remaining $25 to invest in a 7-year option that pays off (some percentage 


For a regular payoff (non-quanto), you would receive, not the expression above, but something similar converted into US dollars. This would make sense, since it would be natural (for an option buyer) to convert the $25 into Japanese yen, buy some units of the Nikkei index, keeping only the increase (not losing money if it falls below the initial level), then converting the profits back to US dollars after 7 years. If we wrote this as an “non-quanto” option payoff, it would be 


If you buy a “quanto” option, you bear no exposure to the vagaries of the FX rate between the US dollar and the Japanese yen, so it is easy to explain and sell to investors. Just look at the first payoff formula above. The second payoff formula, though natural, is a more complex formula.
However, as you should know, in finance, if there is a risk in the activity that you do, but you find that you don’t bear this risk in the instrument you have bought, it is because someone else has (presumably without your knowledge) bought this risk from you and has paid (much) less than what it is worth, through the assumptions used in pricing the instrument you just bought.
It turns out that option pricing formula invented by Fischer Black, Myron Scholes and Robert Merton can be expanded to value these sorts of “quanto” options. The formula depends on some extra parameters. One of these is the volatility (standard deviation per year) of the Yen-dollar exchange rate. The other is the correlation between two quantities – the 


You are asked to buy this correlation, in competition with others. How much would you pay? If you were in an uncompetitive environment, you might “buy” this correlation at 

How seriously should one take this correlation? Consider the cases considered in this fantastic post. A correlation between Manoj “Night” Shyamalan’s movies and newspaper reading? Really? What correlations are sensible and what should we pay less heed to?
The idea of p-values answer the first question. The way to think about the miracle drug is this – suppose you did nothing and you assume (from your prior experience) that the results of doing nothing are – the probability of a patient dying of the deadly disease is 




You might choose to add up the probability that you might get a result of 5 survivals and lower too (in case you are interested in a deviation of 1 or more from the average, rather than just a higher number).

The sum of these two (called the symmetrical p-value) is 0.75, i.e., there is 75% probability that such (and even more hopeful) results are explainable by the “null hypothesis”, that the miracle drug had absolutely no effect and that the disease simply took its usual course.
If we repeated the same test with a 1000 patients, of whom 700 survived, this has a dramatically different result. The same calculations would yield

Notice how small this number is. If you also add the probability of repeating the experiment and getting 500 or fewer survivals, that would be 
The symmetrical p-value in this case is 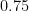
The p-value is just the total probability that the “null hypothesis” generates the observed event or anything even more extreme than observed. Seems reasonable, doesn’t it? If this p-value is less than some lower threshold (say 0.05), you might decide this is acceptable as “evidence”. The 
Next, we come to the underside of p-values. Its called p-hacking. Here’s a simple way to do it. Consider the test where you obtained a 
Another example of p-hacking is one that I gave in this post. For convenience, I reproduce it here –
Imagine you were walking around in Manhattan and you chanced upon an interesting game going on at the side of the road. By the way, when you see these games going on, a safe strategy is to walk on, since they usually reduce to methods of separating a lot of money from you in various ways.
The protagonist, sitting at the table tells you (and you are able to confirm this by a video taken by a nearby security camera run by a disinterested police officer), that he has managed to toss the same quarter (an American coin) thirty times and managed to get “Heads” 
Next, your good friend rushes to your side and whispers to you that this guy is actually one of a 
What if the number of coin tosses was 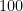
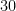
Clearly, you would be p-hacked if you ignored your friend.
p-values are used throughout science, but it is desperately easy to p-hack. It still takes a lot of intellectual honesty and, yes, seat of the pants reasoning and experience to know when you are p-hacking and when you are simply being rational in ignoring certain classes of data.
The q-value is a quantity that describes when a correlation is outside the bonds of the “null hypothesis” – for instance, one might have an economic reason why the fx/equity index correlation is a certain number. Maybe it is linked to the size of trade in/out-flows, tariff structure, the growth in the economy and other aspects. But then, it moves around a lot and clearly follows some kind of random process – just not the one described by the binomial model It would clarify a lot of the nonsense that goes in to price and estimate economic value in products such as quanto options.
More on this in a future post.
Front image : courtesy Hilda Bastian, from this article

Leave a comment