
The Bakhshali manuscript is an artifact discovered in 1881, near the town of Peshawar (in then British India, but now in present-day Pakistan). It is beautifully described in an article in the online magazine of the American Mathematical Society and I spent a few hours fascinated by the description in the article (written excellently by Bill Casselman of the University of British Columbia). It is not clear how old the 70 page manuscript fragment is – its pieces date (using radiocarbon dating) to between 300-1200 AD. However, I can’t imagine this is simply only as old as that – the mathematical tradition it appears to represent, simply by its evident maturity, is much older.
Anyway, read the article to get a full picture, but I want to focus on generalizing the approximation technique described in the article. One of the brilliant sentences in the article referred to above is “Historians of science often seem to write about their subject as if scientific progress were a necessary sociological development. But as far as I can see it is largely driven by enthusiasm, and characterized largely by randomness”. My essay below is in this spirit!
The technique is as follows (and it is described in detail in the article)
Suppose you want to find the square root of an integer 
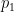


Next, in the manuscript, you are supposed to define, successively

and compute the 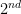

This can go on, according to the algorithm detailed in the manuscript and write

and compute the error term with the same error formula above, with 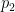

Here comes the generalization (this is not in the Bakhshali manuscript, I don’t know if it is a known technique) – you can use this technique to find higher roots.
Say you want to find the cube root of

Next, define

and compute the

and carry on to define 
The series can be computed in Excel – it converges extremely fast. I computed the cube root of 
Carrying on, we can compute the fourth root of

and so on.
You can generalize this to a general 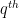






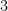
Here’s a bit of the Excel calculation with a starting point of 2
| p | E | |
| p_1 | 2 | -325832 |
| p_2 | 1.93458156 | -80254.8113 |
| p_3 | 1.90526245 | -10060.9486 |
| p_4 | 1.90042408 | -226.670119 |
| p_5 | 1.90030997 | -0.12245308 |
| p_6 | 1.90030991 | -3.6118E-08 |
| p_7 | 1.90030991 | 0 |
and here’s a starting point of 3. Notice how much larger the initial error is (under the column E).
| p | E | |
| p_1 | 3 | -1162063011 |
| p_2 | 2.84213222 | -415943298 |
| p_3 | 2.69261765 | -148847120 |
| p_4 | 2.55108963 | -53231970.3 |
| p_5 | 2.41732047 | -19003715.9 |
| p_6 | 2.29140798 | -6750923.06 |
| p_7 | 2.17425159 | -2365355.74 |
| p_8 | 2.06867527 | -797302.733 |
| p_9 | 1.98149708 | -240959.414 |
| p_10 | 1.92430861 | -53439.1151 |
| p_11 | 1.90282236 | -5045.06319 |
| p_12 | 1.90033955 | -58.8097322 |
| p_13 | 1.90030991 | -0.00825194 |
| p_14 | 1.90030991 | 0 : CONVERGED! |
The neat thing about this method is, unlike what Bill Casselman states, you don’t need to start from an initial point that sandwiches the number 

The actual writer of the Bakhshali manuscript did not use decimal notation, but used rational numbers (fractions) to represent decimals, which required an order of magnitude more work to get the arithmetic right! It is also interesting how the numerals used in the manuscript are so close to the numerals I grew up using in Hindi-speaking Mumbai!
Note added: Bill Casselman wrote to me that the use of rational numbers with a large number of digits instead of decimals represents “several orders of magnitude” more difficulty. I have no difficulty in agreeing with that sentiment – if you want the full analysis, read the article.
There is also a scholarly analysis by M N Channabasappa (1974) that predates the AMS article that analyzes the manuscript very similarly.
A wonderful compendium of original articles on math history is to be found at Math10.





Leave a reply to Simply Curious Cancel reply